


1、文本生成算法
2、使用 ONNX 优化 Bloom 3b
3、在 Triton 推理服务器上,结合动态批处理 托管 Bloom 3b
BigScience Large Open-Science Open Access Language(简称BLOOM)是一个大型语言模型。开源可商用。BLOOM 拥有惊人的 1760 亿参数,并在 1.5 TB 的预处理文本语料库上进行训练,训练运行耗时 117 天,文本包含 46 种自然语言和 13 种编程语言。BLOOM 的较小版本(有 7b、3b 1.7b 和 530m 参数)也可供使用。
BLOOM 3b

decoder-only 结构
Bloom 3b可以通过简单地从BigScience加载模型和分词器来使用:
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-3b")
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-3b")Bloom 3b 用于文本生成
通过计算每个单词在 T+1 处的概率,给定时间 T 处的单词,并应用 softmax 函数来创建下一个单词概率数组来实现这一点。这种自回归语言生成可以通过多种解码方法实现。
Greedy Search:
贪婪搜索的工作原理是选择概率最高的单词作为生成序列中的下一个单词,并重复此过程,直到达到生成文本的所需长度。忽略所有其他可能的单词。
实现此算法只需要一行:
next_token = torch.argmax(next_token_logits, dim=-1)尽管贪婪搜索会产生有意义的文本,但它很快就会变得重复,因为它开始连续输出相同的序列。这在文本生成模型中相当常见。贪婪搜索的另一个限制是,它可能会错过隐藏在较低概率单词后面的更有意义的序列。
Beam Search
Beam Search是一种文本生成策略,它通过考虑每一步中最有可能的下一个单词(不是只有一个单词)来扩展贪婪搜索方法。根据其概率分数选择前 k 个单词,并重复该过程,直到达到生成文本的所需长度。这种方法可以产生比贪婪搜索方法更多样化和更具创造性的文本。
beam_output = model.generate(input_ids, max_length=60, num_beams=2, early_stopping=True)
print(tokenizer.decode(beam_output[0]))“k”或上述代码中的参数 num_beams 称为“波束宽度”。尽管 Beam Search 始终会比 Greedy Search 产生更有意义的输出,但它仍然不能保证输出最佳序列。波段搜索还具有重复生成的缺点,文本通常变得无聊且可预测。
能不能加一些随机性?
Nucleus Filtering
Nucleus Filtering也称为 Top-P 过滤,涉及从前 k 个最可能的单词中选择下一个单词,这些单词共同具有“p”的累积概率。“p”的值决定了应在生成的文本中引入多少随机性或变化性。
简单 Top-P 实现
top_p_output = model.generate(input_ids, do_sample = True, max_length = 60, top_p = 0.6)
print(tokenizer.decode(top_p_output[0]))Python 中实现 Nucleus :
def top_p_filtering(logits, top_p = 1.0, min_tokens_to_keep = 1):
"""
Filter a distribution of logits using nucleus (top-p) filtering
Args:
- logits: logits distribution shape (batch size, vocabulary size)
- if top_p < 1.0: keep the top tokens with cumulative probability >= top_p {nucleus filtering, as described in Holtzman et al (http://arxiv.org/abs/1904.09751)}.
- Make sure we keep at least min_tokens_to_keep per batch example in the output
"""
if top_p < 1.0:
logits_after_sorting, indices_after_sorting = torch.sort(logits, descending=True)
probability_cumulative = torch.cumsum(F.softmax(logits_after_sorting, dim=-1), dim=-1)
# Removing tokens with cumulative probability above the threshold
indices_for_removal = probability_cumulative > top_p
if min_tokens_to_keep > 1:
# Keeping at least min_tokens_to_keep (setting to min_tokens_to_keep-1 because we're adding the first one below)
indices_for_removal[..., :min_tokens_to_keep] = 0
# Shifting the indices to the right to also keep the first token above the threshold
indices_for_removal[..., 1:] = indices_for_removal[..., :-1].clone()
indices_for_removal[..., 0] = 0
# Sorted tensors to original indexing
indices_to_remove = indices_for_removal.scatter(1, indices_after_sorting, indices_for_removal)
logits[indices_to_remove] = filter_value
return logitsONNX
ONNX (Open Neural Network Exchange)是一种用于表示深度学习模型的开源格式。它的工作原理是定义一组通用的运算符和通用的文件格式,以实现一系列工具、框架、编译器和硬件之间的更大互操作性。

要将我们的 Bloom 模型导出到 ONNX,我们只需使用 transformers.onnx.export 函数。该工具通过向图形发送一些虚拟数据并在模型内“跟踪”它来猜测图形的外观。
转换脚本:
# Import the required libraries
from pathlib import Path
import transformers
from transformers.onnx import FeaturesManager
from transformers import AutoConfig, AutoTokenizer, AutoModelForCausalLM
import onnx
# Load the Model & Tokenizer
model_id = "bigscience/bloom-3b"
feature = "causal-lm"
model = AutoModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Load Config
model_kind, model_onnx_config = FeaturesManager.check_supported_model_or_raise(model, feature= feature)
onnx_config = model_onnx_config(model.config)
# Export the model to ONNX
onnx_inputs, onnx_outputs = transformers.onnx.export(
preprocessor= tokenizer,
model= model,
config= onnx_config,
opset= 12,
output= Path("destination_path/model.onnx")
)
# Load and check model
model = onnx.load()
onnx.checker.check_model('destination_path/model.onnx')
onnx.shape_inference.infer_shapes_path('destination_path/trfs-model.onnx', 'model.onnx')现在模型采用 ONNX 格式,还可以怎么优化它?
删除冗余操作:某些操作可能对模型不是必需的,它会占用空间和计算能力,而不会对输出做出贡献,可以删除。
常量折叠:模型中常量表达式的结果可以在编译时计算,而不是在运行时,这样可以减少实现时间。
内核融合:操作可以合并在一起,避免单独的加载时间,并减少进出全局内存的内存传输次数。
量化:模型权重可以转换为较轻的表示形式。这可能会在一定程度上降低模型的准确性。例如16bit 8bit量化等
实时推理Triton
Triton Server是一个高性能推理服务器,可以大规模运行深度学习模型,而Triton Client提供了一个易于使用的API来与Triton Server进行交互。
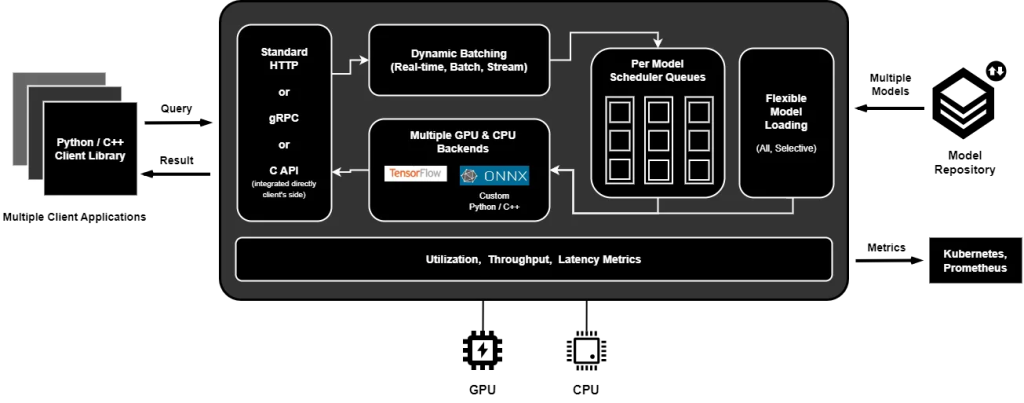
安装triton
pip install tritonclient[all]
修改配置
将模型上传到模型存储库Model Repository:必须首先将模型及其元数据metadata(包括版本信息、输入/输出格式和模型配置)上传到服务器的模型存储库。
Configuring the Bloom 3b Tokenizer
name: "bloom_3b_tokenizer"
max_batch_size: 0
backend: "python"
input [
{
name: "TEXT"
data_type: TYPE_STRING
dims: [ -1 ] # Dynamic Batching: the -1 acts as a dynamic size - it is automatically adjusts to the size of the current input sequence without us having to provide individual lengths for differently sized inputs.
}
]
output [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [-1, -1] # Dynamic Batching for a 2D array
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [-1, -1]
}
]
instance_group [
{
count: 1
kind: KIND_CPU
}
]Configuring the Bloom 3b Model
name: "bloom_3b"
platform: "onnxruntime_onnx"
max_batch_size : 0
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [ -1, -1 ] # Dynamic Batching
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [ -1, -1 ]
}
]
output [
{
name: "logits"
data_type: TYPE_FP32
dims: [ -1, -1, 250880]
label_filename: "label.txt"
}
]
instance_group [
{
count: 1
kind: KIND_CPU
}
]加载模型:
模型加载器从模型存储库加载模型,并执行任何必要的优化,例如精度校准和量化。
import ast
import numpy as np
import tritonclient.grpc as grpcclient
from transformers import AutoTokenizer
class BLOOM_3B(object):
def __init__(self, cfg):
self.input_names = ast.literal_eval(cfg["bloom_3b"]["input_names"])
self.input_dtypes = ast.literal_eval(cfg["bloom_3b"]["input_dtypes"])
self.output_names = ast.literal_eval(cfg["bloom_3b"]["output_names"])
self.input_shape_input_ids = None
self.input_shape_att_masks = None
class BLOOM_3B_TOKENIZER(object):
def __init__(self, cfg):
self.input_names = ast.literal_eval(cfg["bloom_3b_tokenizer"]["input_names"])
self.input_dtypes = ast.literal_eval(cfg["bloom_3b_tokenizer"]["input_dtypes"])
self.output_names = ast.literal_eval(cfg["bloom_3b_tokenizer"]["output_names"])
self.text = None
self.ids = None发送推理请求:
客户端可以通过 HTTP API 或 gRPC 向服务器发送推理请求,以及模型的输入数据和模型所需的任何其他元数据。
sudo docker run --rm --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -p 8062:8062 -p 8063:8063 -p 8064:8064 --net=host -v $PWD/models:/models nvcr.io/nvidia/tritonserver:20.12-py3 bash -c "pip install transformers && tritonserver --model-repository=/models --http-port 8062 --grpc-port 8063 --metrics-port 8064 --log-verbose=1"执行推理:
推理引擎使用服务器上的可用硬件资源对加载的模型执行实际推理。
# Tokenizer Inferencing
st_text_op = trt_client.infer(
model_name=cfg["bloom_3b_tokenizer"]["model_name"],
model_version='1',
inputs=st_token_i,
outputs=st_token_io_buf_output,
client_timeout=None,
)# Model Inferencing
st_o = trt_client.infer(
model_name=cfg["bloom_3b"]["model_name"],
model_version='1',
inputs=st_i,
outputs=st_io_buf_output,
client_timeout=None,
)gRPC对比HTTP
更快、更高效:
二进制编码:gRPC 使用协议缓冲区二进制编码格式,该格式比 HTTP 使用的人类可读 JSON 或 XML 格式更紧凑、更高效。
多路复用:gRPC 可以通过单个 TCP 连接多路复用多个请求和响应,从而减少设置和拆除多个连接的开销。
流式处理:gRPC 支持双向流式处理,它允许客户端和服务器通过单个连接发送多条消息,而无需等待每条消息的响应。
代码生成:gRPC 从服务定义文件生成客户端和服务器代码,从而减少开发人员需要编写的样板代码量。
性能优化:gRPC 使用各种性能优化(如连接池和流控制)来提高性能并减少延迟。
强类型:gRPC 使用服务定义文件来定义 API,该 API 为请求和响应提供强类型。
互操作性:gRPC 支持多种编程语言和平台,这使得构建和维护分布式系统变得更加容易。
安全性:gRPC 提供对传输级安全性 (TLS) 的内置支持,可确保数据在传输过程中加密且安全。
参考
https://github.com/triton-inference-server/server/blob/main/README.md
https://github.com/triton-inference-server/server/blob/main/docs/getting_started/quickstart.md
https://github.com/DANNALI35/zhihu_article/blob/master/202202_triton/triton.ipynb
https://zhuanlan.zhihu.com/p/471291236