https://huggingface.co/bigscience/bloom
问题:
Bloom是如何一步步设计的?
用了哪些数据和硬件资源?
模型结构细节是怎样的?
训练细节是怎样的?
Bloom是如何一步步设计
1、人员组织
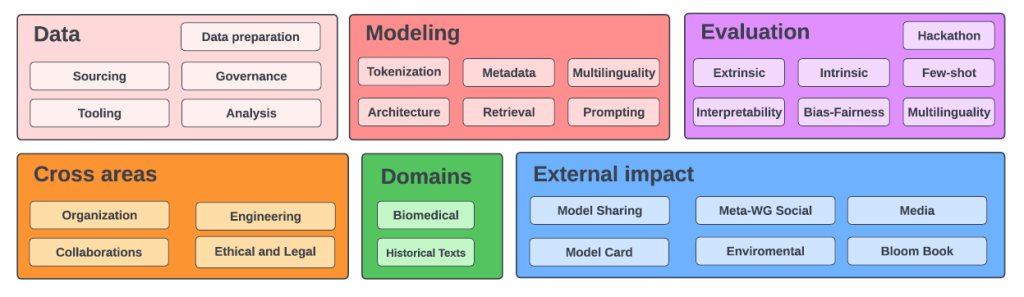
做大模型的人力资源调配,工作任务分配等,主要是这几个方面。
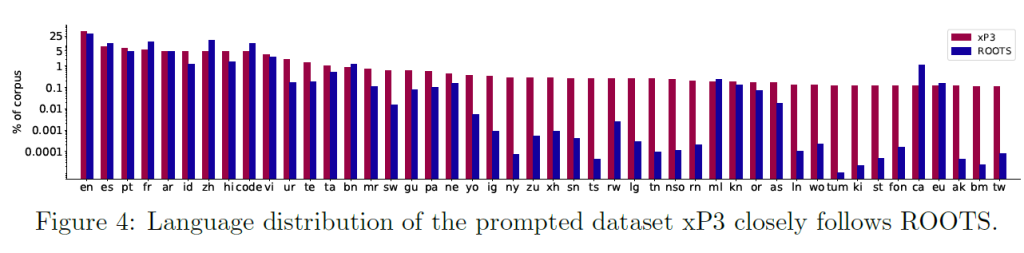
2、Dataset数据集
跨越59种语言的1.6TB数据集 ROOTS corpus: https://openreview.net/forum?id=UoEw6KigkUn

数据连接:
https://github.com/bigscience-workshop/data-preparation
https://huggingface.co/bigscience-data
重复数据删除和隐私编辑
3、模型结构
模型设计细节可以参考这两篇论文:
https://proceedings.mlr.press/v162/wang22u/wang22u.pdf
https://openreview.net/pdf?id=rI7BL3fHIZq
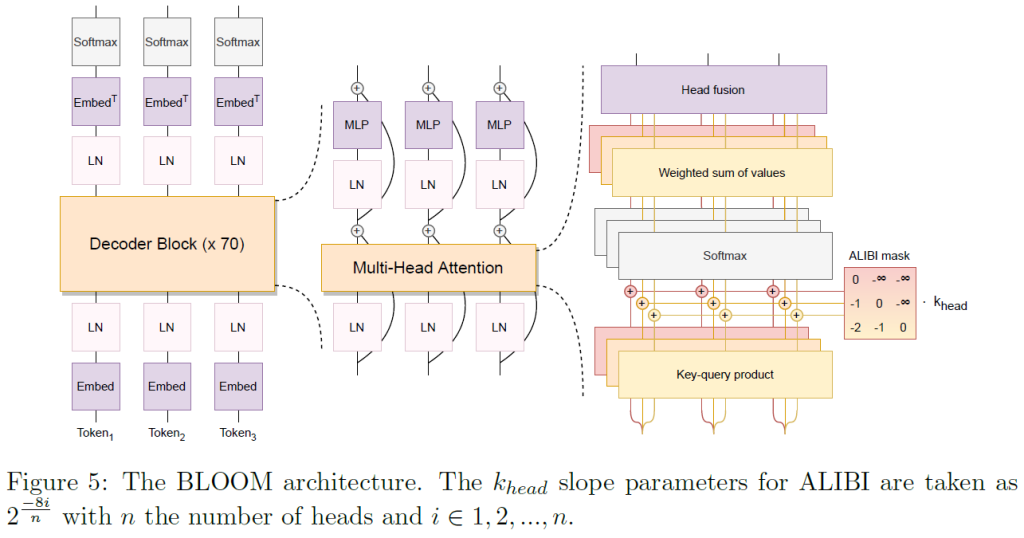
研究者们评估了编码器-解码器和仅解码器架构及其与因果、前缀和掩蔽语言建模预训练目标的相互作用:we evaluated encoder-decoder and decoder-only architectures and their interactions with causal, prefix, and masked language modeling pretraining objectives.
结果表明:在预训练后,因果解码器模型立即表现最好,因此作为LLM的选择。在预训练后,它们可以更有效地适应非因果架构和目标。
改进:
ALiBi Positional Embeddings:
ALiBi不是在嵌入层添加位置信息,而是根据键和查询的距离直接衰减注意力分数。【上图中最右侧】
Embedding LayerNorm:
在训练104B模型的时候,在嵌入层之后加额外的层归一化,这个在bitsandbytes库的StableEmbedding层有应用,增强了训练稳定性。同时,float16是训练LLM中不稳定的原因之一,所以最后训练的时候用的是bfloat16。
4、Tokenization

目标:多语言分词器与相应语言的单语分词器进行比较,不会将每种语言的fertility降低超过 10 个百分点。
使用了 Byte-level BPE算法,并做了pre-tokenizer预处理,最终使用了 250680 个tokens,其中预留了 200 个token【placeholder tokens】。词汇量大小决定嵌入矩阵大小,出于 GPU 效率原因,可被 128 整除,可被 4 整除,这样就能能够使用张量并行。
资源
硬件资源
训练 BLOOM 大约需要 3.5 个月才能完成,消耗了 1082990 个计算小时,384个A100 80GB GPUs。节点配备了2个AMD EPYC 7543 32核CPU和512 GB RAM,而存储则由全闪存和硬盘驱动器混合处理,使用SpectrumScale(GPFS)并行文件系统在超级计算机的所有节点和用户之间共享。每个节点 4 个 NVLink GPU 到 GPU 互连启用节点内通信,每个节点的 Gbps 链路 4 个 Omni-Path 100,排列在增强型超立方体 8D 中全局拓扑,用于节点间通信。
Framework:

Bloom训练的时候使用了Megatron-DeepSpeed,提供Transformer实现、张量并行性和数据加载,而 DeepSpeed提供了 ZeRO 优化器、模型流水线和通用分布式训练组件。该框架使我们能够使用 3D 并行性进行高效训练【如图】。
Data parallelism:复制模型的副本放置在不同的设备上,发送数据,处理是并行完成的,所有模型副本在每个训练步骤结束时同步。
Tensor parallelism:跨多个设备分割模型的各个层,不必将整个激活或梯度张量驻留在单个 GPU 上,而是将该张量的分片放置在单独的 GPU 上。
Pipeline parallelism:将模型的层拆分到多个 GPU 上,以便每个 GPU 上仅放置模型层的一小部分。
零冗余优化器(ZeRO)允许不同的过程只保存训练步骤所需的一小部分数据(例如:parameters, gradients, and optimizer states)
三个框架的开源代码:
https://github.com/bigscience-workshop/Megatron-DeepSpeed
https://github.com/NVIDIA/Megatron-LM
https://github.com/microsoft/DeepSpeed
我们能够使用 A100 GPU 以最快的配置实现 156 TFLOP,实现 312 TFLOPs 理论峰值性能的一半目标(浮点 32 或 bfloat16).
float16是一种 16 位浮点格式,动态范围非常有限,可能导致溢出,进而训练不稳。bfloat16 具有与 float32 相同的动态范围,但精度仍然低得多,这促使我们使用混合精度训练。某些精度敏感的操作,例如 float32 精度的梯度累积和 softmax,其余操作使用较低精度,这促使实现高性能和训练稳定性的平衡。
我们使用了Megatron-LM提供的几个定制的融合CUDA内核。首先,使用优化的内核来执行 LayerNorm,并使用内核来融合缩放、屏蔽和 softmax 操作(scaling, masking, and softmax)的各种组合。偏置项bias的添加和GeLU 激活融合也与 JIT 功能融合一起,例如:在 GeLU 操作中添加偏置项不会增加额外的时间,因为该操作是内存限制的,与 GPU VRAM 和寄存器之间的数据传输相比,额外的计算可以忽略不计,因此融合这两个操作基本上将其运行时间减半。
扩展到 384 个 GPU 需要两个最终更改:禁用异步 CUDA 内核启动(为了便于调试并防止死锁)和将参数组拆分为更小的子组(以避免过多的 CPU 内存分配)。在训练期间,存在硬件故障的问题:平均每周发生 12 次 GPU 故障。由于备份节点可用并自动使用,并且检查点每三个小时保存一次,因此这不会显著影响训练吞吐量。数据加载器中的 PyTorch 死锁错误和磁盘空间问题导致 510 小时停机。
点击查看更多技术细节 。
Training
超参数

耗能产碳量:
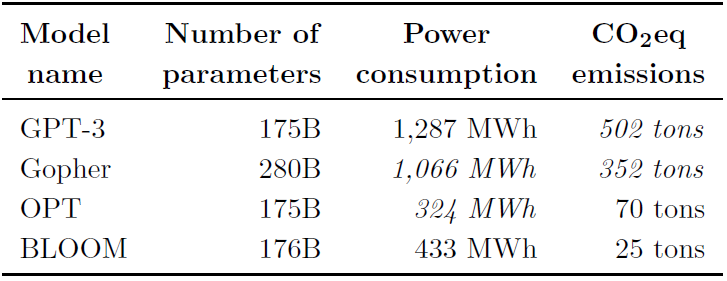
从这里的参数量对比,Bloom 176B对标的是GPT3和OPT呀~
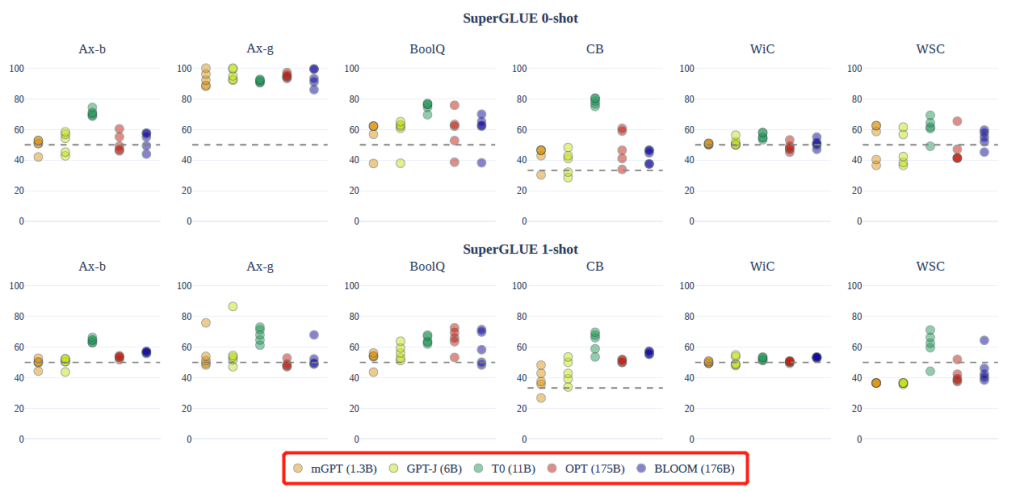
评估
我们的评估侧重于zero-shot 和few-shot,在SuperGLUE、Machine Translation、Summarization等方面做了评测,对比模型和结果: