数据并行
数据并行,就是将数据集分为N份,分别装载到N个GPU节点中,每个GPU节点持有一个完整的模型副本,分别基于每个GPU中的数据去进行梯度求导。在GPU0上对每个GPU中的梯度进行累加,最后,再将GPU0聚合后的结果广播到其他GPU节点。数据并行不仅仅指对训练的数据并行操作,还可以对网络模型梯度、权重参数、优化器状态等数据进行并行。
数据并行
数据并行(torch.nn.DataParallel),基于单进程多线程进行实现的,使用一个进程来计算模型权重,在每个批处理期间将数据分发到每个GPU。
DataParallel 的计算过程如下所示:
- 将 inputs 从主 GPU 分发到所有 GPU 上。
- 将 model 从主 GPU 分发到所有 GPU 上。
- 每个 GPU 分别独立进行前向传播,得到 outputs。
- 将每个 GPU 的 outputs 发回主 GPU。
- 在主 GPU 上,通过 loss function 计算出 loss,对 loss function 求导,求出损失梯度。
- 计算得到的梯度分发到所有 GPU 上。
- 反向传播计算参数梯度。
- 将所有梯度回传到主 GPU,通过梯度更新模型权重。
- 不断重复上面的过程。
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
output = net(input_var) # input_var can be on any device, including CPU分布式数据并行
PyTorch官方建议使用DistributedDataParallel,而不是DataParallel类来进行多 GPU 训练,即使在单机多卡的情况下。那么下面我们来看看PyTorch DDP。
分布式数据并行(torch.nn.DistributedDataParallel),基于多进程进行实现的,每个进程都有独立的优化器,执行自己的更新过程。每个进程都执行相同的任务,并且每个进程都与所有其他进程通信。进程(GPU)之间只传递梯度,这样网络通信就不再是瓶颈。DistributedDataParallel方式可以更好地进行多机多卡运算,更好的进行负载均衡,运行效率也更高,虽然使用起来较为麻烦,但对于追求性能来讲是一个更好的选择。
具体流程如下:
- 首先将 rank=0 进程中的模型参数广播到进程组中的其他进程;
- 然后,每个 DDP 进程都会创建一个 local Reducer 来负责梯度同步。
- 在训练过程中,每个进程从磁盘加载 batch 数据,并将它们传递到其 GPU。每个 GPU 都有自己的前向过程,完成前向传播后,梯度在各个 GPUs 间进行 All-Reduce,每个 GPU 都收到其他 GPU 的梯度,从而可以独自进行反向传播和参数更新。
- 同时,每一层的梯度不依赖于前一层,所以梯度的 All-Reduce 和后向过程同时计算,以进一步缓解网络瓶颈。
- 在后向过程的最后,每个节点都得到了平均梯度,这样各个 GPU 中的模型参数保持同步 。
import torch
import t dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
main()完全分片数据并行
完全分片数据并行(torch.distributed.fsdp.FullyShardedDataParallel),是Pytorch最新的数据并行方案。PyTorch FSDP 受 DeepSpeed ZeRO 启发而获得灵感:
针对模型状态的存储优化(去除冗余),DeepSpeed 提出了 ZeRO,ZeRO 使用的方法是分片,即每张卡只存 1/N 的模型状态量,这样系统内只维护一份模型状态参数。
ZeRO对 模型状态(Model States)参数进行不同程度的分割,主要有三个不同级别:
- ZeRO-1: 对优化器状态分片(Optimizer States Sharding)
- ZeRO-2 : 对优化器状态和梯度分片(Optimizer States & Gradients Sharding)
- ZeRO-3 : 对优化器状态、梯度分片以及模型权重参数分片(Optimizer States & Gradients & Parameters Sharding)
FSDP 目的主要是用于训练大模型,为了打破模型分片的障碍(包括模型参数,梯度,优化器状态),同时,仍然保持了数据并行的简单性。传统的数据并行维护模型参数、梯度和优化器状态的每个 GPU 副本,而 FSDP 将所有这些状态跨数据并行工作线程进行分片,并且可以选择将模型参数分片卸载到 CPU。
自动包装(Auto Wrapping)
模型层应以嵌套方式包装在 FSDP 中,以节省峰值内存并实现通信和计算重叠。 最简单的方法是自动包装,它可以作为 DDP 的直接替代品,而无需更改其余代码。
fsdp_auto_wrap_policy参数允许指定可调用函数以使用 FSDP 递归地包裹层。 PyTorch FSDP提供的default_auto_wrap_policy函数递归地包裹参数数量大于100M的层。当然,您也可以根据需要提供自己的包装策略。
此外,可以选择配置 cpu_offload,以便在计算中不使用包装参数时将这些参数卸载到 CPU。 这可以进一步提高内存效率,但代价是主机和设备之间的数据传输开销。
from torch.distributed.fsdp import (
FullyShardedDataParallel,
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
default_auto_wrap_policy,
)
import torch.nn as nn
class model(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(8, 4)
self.layer2 = nn.Linear(4, 16)
self.layer3 = nn.Linear(16, 4)
model = DistributedDataParallel(model())
fsdp_model = FullyShardedDataParallel(
model(),
fsdp_auto_wrap_policy=default_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True),
)手动包装(Manual Wrapping)
通过有选择地对模型的某些部分应用包装,手动包装对于探索复杂的分片策略非常有用。 总体设置可以传递给enable_wrap()上下文管理器。
from torch.distributed.fsdp import (
FullyShardedDataParallel,
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
enable_wrap,
wrap,
)
import torch.nn as nn
from typing import Dict
class model(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = wrap(nn.Linear(8, 4))
self.layer2 = nn.Linear(4, 16)
self.layer3 = wrap(nn.Linear(16, 4))
wrapper_kwargs = Dict(cpu_offload=CPUOffload(offload_params=True))
with enable_wrap(wrapper_cls=FullyShardedDataParallel, **wrapper_kwargs):
fsdp_model = wrap(model())使用上述两种方法之一,用 FSDP 包装模型后,可以采用与本地训练类似的方式训练模型:
optim = torch.optim.Adam(fsdp_model.parameters(), lr=0.0001)
for sample, label in next_batch():
out = fsdp_model(input)
loss = criterion(out, label)
loss.backward()
optim.step()在FullyShardedDataParallel训练方法中:
- Model shard:每个GPU上仅存在模型的分片。
- All-gather:每个GPU通过all-gather从其他GPU收集所有权重,以在本地计算前向传播。
- Forward(local):在本地进行前向操作。前向计算和后向计算都是利用完整模型。
- All-gather:然后在后向传播之前再次执行此权重收集。
- Backward(local):本地进行后向操作。前向计算和后向计算都是利用完整模型,此时每个GPU上也都是全部梯度。
- Reduce-Scatter:在向后传播之后,局部梯度被聚合并且通过 Reduce-Scatter 在各个GPU上分片,每个分片上的梯度是聚合之后本分片对应的那部分。
- Update Weight(local):每个GPU更新其局部权重分片。
流水线并行
FSDP 可以缓解冗余的问题,但是对于超大规模模型来说,仅使用数据并行进行分布式训练没办法使模型的参数规模进一步提升。因此,另一种并行技术是模型并行,即模型被分割并分布在一个设备阵列上,每一个设备只保存模型的一部分参数。
模型并行分为张量并行和流水线并行,张量并行为层内并行,对模型 Transformer 层内进行分割,流水线为层间并行,对模型不同的 Transformer 层间进行分割。就是由于模型太大,无法将整个模型放置到单张GPU卡中;因此,将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练。
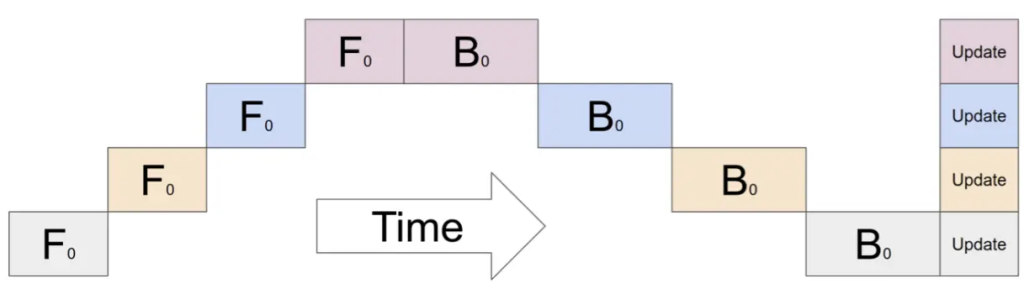

GPipe(Easy Scaling with Micro-Batch Pipeline Parallelism)
Gpipe 流水线并行主要用来解决这两个问题:第一,提高模型训练的并行度。Gpipe 在朴素流水线并行的基础上,利用数据并行的思想,将 mini-batch 细分为多个更小的 micro-batch,送入GPU进行训练,来提高并行程度。第二,通过重计算(Re-materialization)降低显存消耗。在模型训练过程中的前向传播时,会记录每一个算子的计算结果,用于反向传播时的梯度计算。
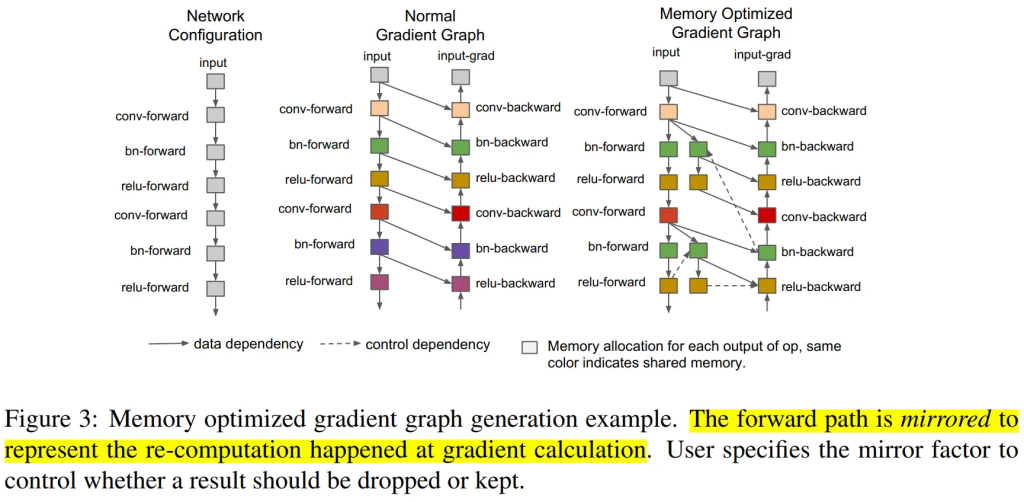
Gpipe 的流水线有以下几个问题:
- 将 mini-batch 切分成 m 份 micro-batch 后,将带来更频繁的流水线刷新(Pipeline flush),这降低了硬件效率,导致空闲时间的增加。
- 将 mini-batch 切分成 m 份 micro-batch 后, 需要缓存 m 份 activation,这将导致内存增加。原因是每个 micro-batch 前向计算的中间结果activation 都要被其后向计算所使用,所以需要在内存中缓存。即使使用了重计算技术,前向计算的 activation 也需要等到对应的后向计算完成之后才能释放。
基于PyTorch使用包含两个 FC 层的模型跨 GPU0 和 GPU1 进行流水线并行的示例:
# Need to initialize RPC framework first.
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
torch.distributed.rpc.init_rpc('worker', rank=0, world_size=1)
# 构建模型
fc1 = nn.Linear(16, 8).cuda(0)
fc2 = nn.Linear(8, 4).cuda(1)
model = nn.Sequential(fc1, fc2)
from torch.distributed.pipeline.sync import Pipe
# chunks表示micro-batches的大小,默认值为1
model = Pipe(model, chunks=8)
input = torch.rand(16, 16).cuda(0)
output_rref = model(input)
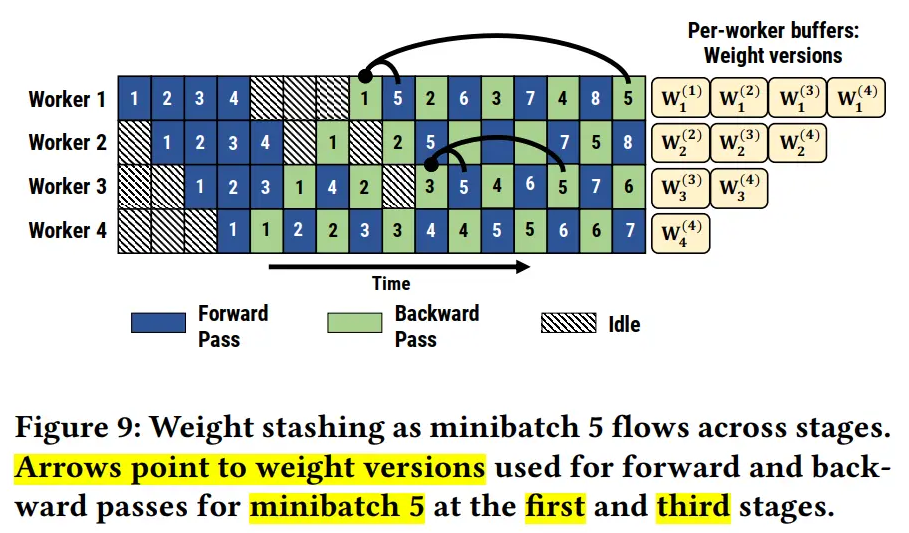
PipeDream(非交错式1F1B)-DeepSpeed
PipeDream 具体方案如下:
- 一个阶段(stage)在做完一次 micro-batch 的前向传播之后,就立即进行 micro-batch 的后向传播,然后释放资源,那么就可以让其他 stage 尽可能早的开始计算,这就是 1F1B 策略。有点类似于把整体同步变成了众多小数据块上的异步,而且众多小数据块都是大家独立更新。
- 在 1F1B 的稳定状态(steady state,)下,会在每台机器上严格交替的进行前向计算/后向计算,这样使得每个GPU上都会有一个 micro-batch 数据正在处理,从而保证资源的高利用率(整个流水线比较均衡,没有流水线刷新(Pipeline Flush),这样就能确保以固定周期执行每个阶段上的参数更新。
- 面对流水线带来的异步性,1F1B 使用不同版本的权重来确保训练的有效性。
张量并行
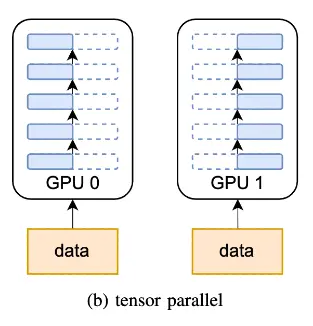
和流水线并行类似,张量并行也是将模型分解放置到不同的GPU上,以解决单块GPU无法储存整个模型的问题。和流水线并行不同的地方在于,张量并行是针对模型中的张量进行拆分,将其放置到不同的GPU上。
模型并行是不同设备负责单个计算图不同部分的计算。而将计算图中的层内的参数(张量)切分到不同设备(即层内并行),每个设备只拥有模型的一部分,以减少内存负荷,我们称之为张量模型并行。张量并行从数学原理上来看就是对于linear层就是把矩阵分块进行计算,然后把结果合并;对于非linear层,则不做额外设计。
张量切分方式分为按行进行切分和按列进行切分,分别对应行并行(Row Parallelism)与列并行(Column Parallelism)
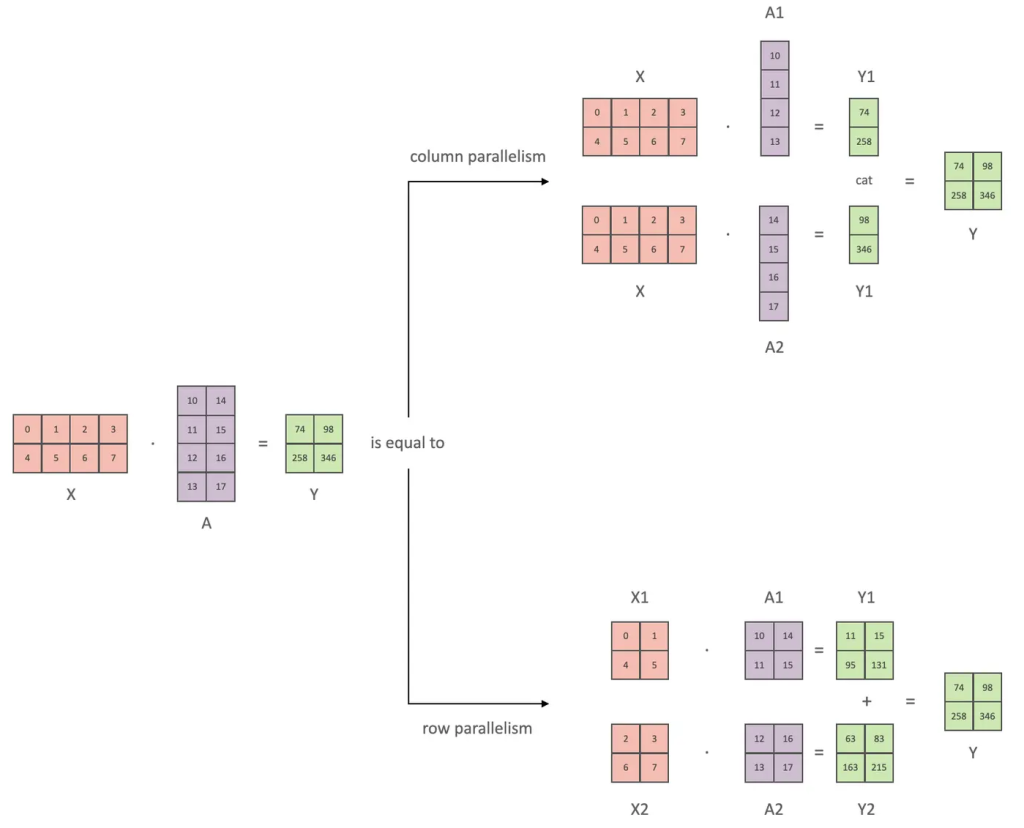
行并行:
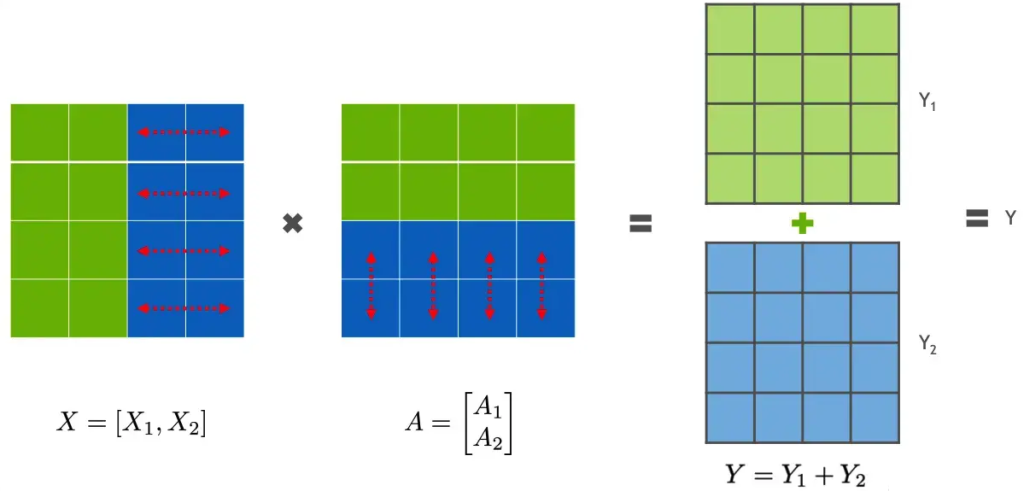
行并行就是把权重 A 按照行分割成两部分。为了保证运算,同时我们也把 X 按照列来分割为两部分,这样,X1 和 A1 就可以放到 GPU0 之上计算得出 Y1,,X2 和 A2 可以放到第二个 GPU1 之上计算得出 Y2,然后,把Y1和Y2结果相加,得到最终的输出Y。
列并行
列并行就是把 A按照列来分割,将 X 分别放置在GPU0 和GPU1,将 A1 放置在 GPU0,将 A2 放置在 GPU1,然后分别进行矩阵运行,最终将2个GPU上面的矩阵拼接在一起,得到最终的输出Y。
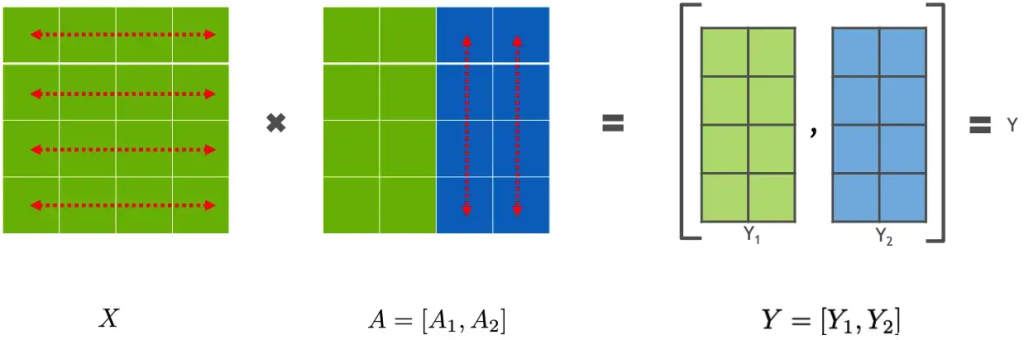
1维(1D)张量并行(Megatron-LM)
张量并行则涉及到不同的分片 (sharding)方法,现在最常用的都是 1D 分片,即将张量按照某一个维度进行划分(横着切或者竖着切)。
目前,在基于Transformer架构为基础的大模型中,最常见的张量并行方案由Megatron-LM提出,它是一种高效的一维(1D)张量并行实现。它采用的则是非常直接的张量并行方式,对权重进行划分后放至不同GPU上进行计算。
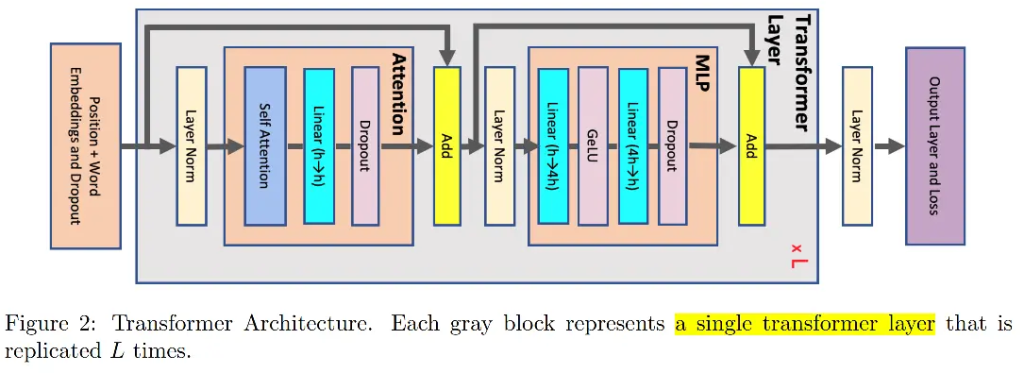
如下图所示,对于一个基于 Transformer 结构的模型来说,主要由一个 N 层 Transformer 块组成,除此之外还有输入和输出 Embedding 层。而一个 Transformer 层里面主要由由自注意力(Self-Attention)和 MLP 组成。因此,本方案主要针对多头注意力(MHA)块和MLP块进行切分进行模型并行。
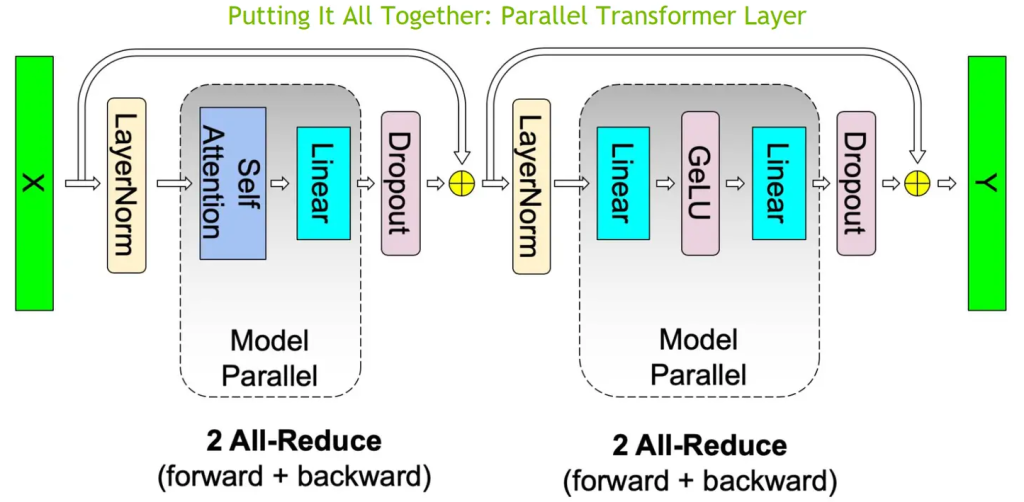
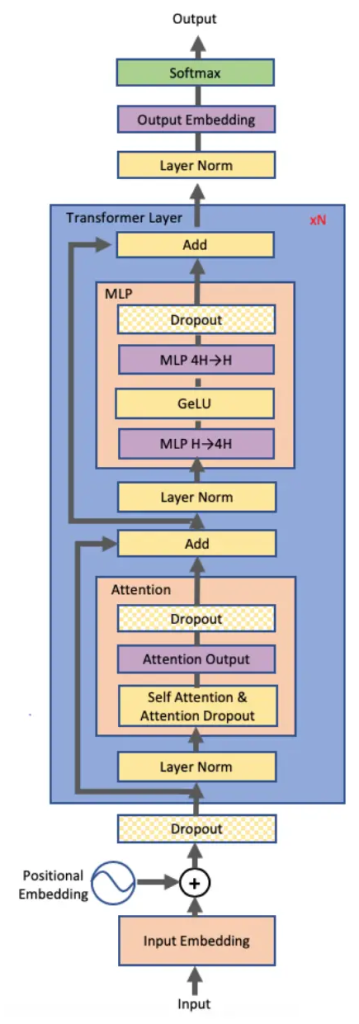
将 Embeding 层 GEMM 进行并行化是非常有益的。然而,在Transformer语言模型中,为了节约内存,通常输出 Embeding 层与输入 Embeding 层共享权重,因此,需要对两者进行修改。
在Embbedding层,按照词的维度切分,即每张卡只存储部分词向量表,然后,通过 All Gather 汇总各个设备上的部分词向量结果,从而得到完整的词向量结果
在 Megatron-LM 中,通过如下方法来初始化张量并行、流水线并行以及数据并行组。
from megatron.core import mpu, tensor_parallel
mpu.initialize_model_parallel(args.tensor_model_parallel_size,
args.pipeline_model_parallel_size,
args.virtual_pipeline_model_parallel_size,
args.pipeline_model_parallel_split_rank)
2D张量并行
Megatron中的 1D 张量并行方案并没有对激活(activations)进行划分,对于大模型而言,这也会消耗大量的内存。为了平均分配计算和内存负荷,在 SUMMA 算法(一种可扩展的通用矩阵乘法算法,并行实现矩阵乘法)的基础上,把 input 和 weight 都沿着两个维度均匀切分。
在 Colossal-AI 中,2D 张量并行示例如下所示:
import colossalai
import colossalai.nn as col_nn
import torch
from colossalai.utils import print_rank_0
from colossalai.context import ParallelMode
from colossalai.core import global_context as gpc
from colossalai.utils import get_current_device
# 并行设置
CONFIG = dict(parallel=dict(
data=1,
pipeline=1,
tensor=dict(size=4, mode='2d'),
))
parser = colossalai.get_default_parser()
colossalai.launch(config=CONFIG,
rank=args.rank,
world_size=args.world_size,
local_rank=args.local_rank,
host=args.host,
port=args.port)
class MLP(torch.nn.Module):
def __init__(self, dim: int = 256):
super().__init__()
intermediate_dim = dim * 4
self.dense_1 = col_nn.Linear(dim, intermediate_dim)
print_rank_0(f'Weight of the first linear layer: {self.dense_1.weight.shape}')
self.activation = torch.nn.GELU()
self.dense_2 = col_nn.Linear(intermediate_dim, dim)
print_rank_0(f'Weight of the second linear layer: {self.dense_2.weight.shape}')
self.dropout = col_nn.Dropout(0.1)
def forward(self, x):
x = self.dense_1(x)
print_rank_0(f'Output of the first linear layer: {x.shape}')
x = self.activation(x)
x = self.dense_2(x)
print_rank_0(f'Output of the second linear layer: {x.shape}')
x = self.dropout(x)
return x
# 创建模型
m = MLP()
# 随机输入一些数据来运行这个模型
x = torch.randn((16, 256), device=get_current_device())
# partition input
torch.distributed.broadcast(x, src=0)
x = torch.chunk(x, 2, dim=0)[gpc.get_local_rank(ParallelMode.PARALLEL_2D_COL)]
x = torch.chunk(x, 2, dim=-1)[gpc.get_local_rank(ParallelMode.PARALLEL_2D_ROW)]
print_rank_0(f'Input: {x.shape}')
x = m(x)2.5D张量并行
之所以叫 2.5D 张量并行是因为在 d = 1 时,这种并行模式可以退化成 2D 张量并行;在 d = q 时,它就变成了3D 张量并行。
在 Colossal-AI 中,2.5D 张量并行示例如下所示:
# 并行设置
CONFIG = dict(parallel=dict(
data=1,
pipeline=1,
tensor=dict(size=8, mode='2.5d', depth=2),
))
...
# 创建模型
m = MLP()
# 随机输入一些数据来运行这个模型
x = torch.randn((16, 256), device=get_current_device())
# partition input
torch.distributed.broadcast(x, src=0)
x = torch.chunk(x, 2, dim=0)[gpc.get_local_rank(ParallelMode.PARALLEL_2P5D_DEP)]
x = torch.chunk(x, 2, dim=0)[gpc.get_local_rank(ParallelMode.PARALLEL_2P5D_COL)]
x = torch.chunk(x, 2, dim=-1)[gpc.get_local_rank(ParallelMode.PARALLEL_2P5D_ROW)]
print_rank_0(f'Input: {x.shape}')
x = m(x)
3D张量并行
3D 并行矩阵乘法对矩阵做了广播,造成了很大的内存冗余。
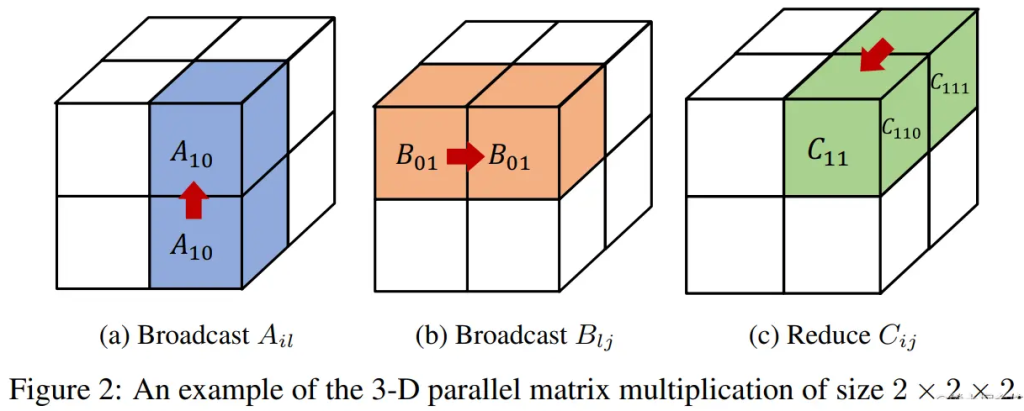
为了去除掉这种冗余性,Colossal-AI 把模型的矩阵进一步做了一个细粒度的划分。
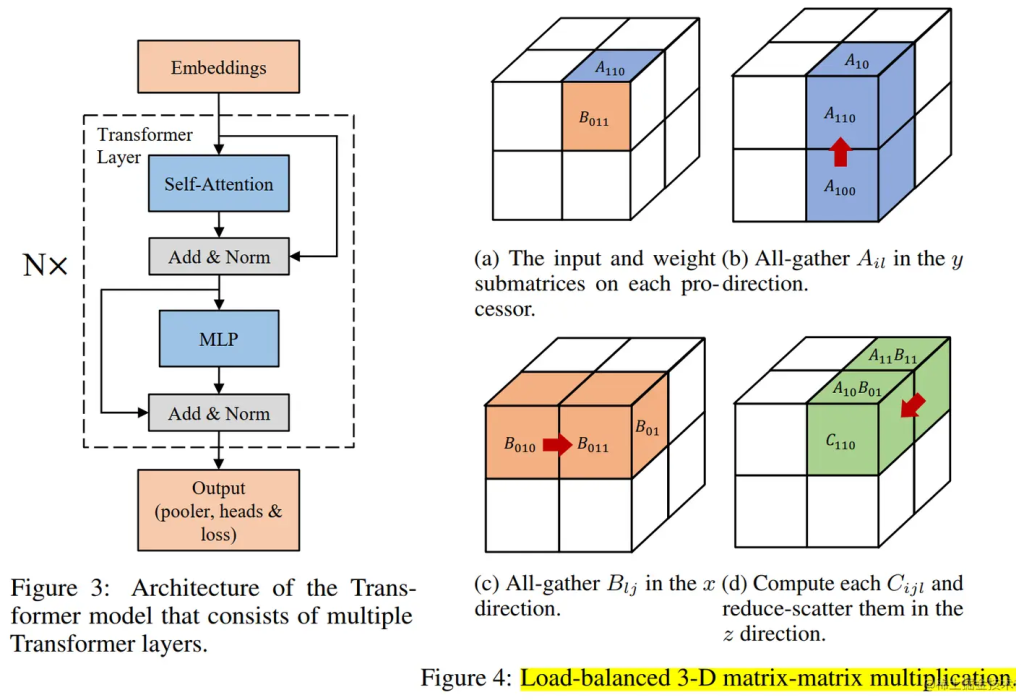
Colossal-AI 的 3D 张量并行是一种将神经网络模型的计算并行化,以期望获得最佳通信成本优化的方法。与现有的 1D 和 2D 张量并行相比,具有更少的内存和网络通信开销。
在 Colossal-AI 中,3D 张量并行示例如下所示:
# 并行设置
CONFIG = dict(parallel=dict(
data=1,
pipeline=1,
tensor=dict(size=8, mode='3d'),
))
...
# 创建模型
m = MLP()
# 随机输入一些数据来运行这个模型
x = torch.randn((16, 256), device=get_current_device())
# partition input
torch.distributed.broadcast(x, src=0)
x = torch.chunk(x, 2, dim=0)[gpc.get_local_rank(ParallelMode.PARALLEL_3D_WEIGHT)]
x = torch.chunk(x, 2, dim=0)[gpc.get_local_rank(ParallelMode.PARALLEL_3D_INPUT)]
x = torch.chunk(x, 2, dim=-1)[gpc.get_local_rank(ParallelMode.PARALLEL_3D_OUTPUT)]
print_rank_0(f'Input: {x.shape}')
x = m(x)Pytorch中的张量并行
PyTorch 从 2.0.0 开始引入 DTensor 作为下一代 ShardedTensor,为分布式存储和计算提供基本抽象。它作为分布式程序翻译和描述分布式训练程序的布局的基本构建块之一。通过DTensor抽象,我们可以无缝构建张量并行、DDP和FSDP等并行策略
PyTorch DTensor 主要用途:
- 提供在 checkpointing 期间保存/加载 state_dict 的统一方法,即使存在复杂的张量存储分配策略,例如:将张量并行与 FSDP 中的参数分片相结合。
- 在 eager 模式下启用张量并行。 与 ShardedTensor 相比,DistributedTensor 允许更灵活地混合分片和复制。
- 充当 SPMD 编程模型的入口点和基于编译器的分布式训练的基础构建块。
PyTorch 中张量并行具体示例如下所示:
from torch.distributed._tensor import DeviceMesh
from torch.distributed.tensor.parallel import PairwiseParallel, parallelize_module
# 通过设备网格根据给定的 world_size 创建分片计划
device_mesh = DeviceMesh("cuda", torch.arange(0, args.world_size))
# 创建模型并移动到GPU
model = ToyModel().cuda(rank)
# 为并行化模块创建优化器
LR = 0.25
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
# 根据给定的并行风格并行化模块,
# 这里指定为PairwiseParallel,将 colwise 和 rowwise 样式串联为固定对,就像 [Megatron-LM](https://arxiv.org/abs/1909.08053) 所做的那样。
model = parallelize_module(model, device_mesh, PairwiseParallel())
# 对分片模块执行多次前向/后向传播和优化器对参数进行更新。
for i in range(args.iter_nums):
# 对于 TP,所有 TP rank 的输入需要相同。
# 设置随机种子是为了模仿数据加载器的行为。
if rank==0:
print(f"-----------{i}--------------")
torch.manual_seed(i)
inp = torch.rand(20, 10).cuda(rank)
if rank==0:
print(f"rank: {rank} , input shape: {inp.shape}")
output = model(inp)
if rank==0:
print(f"rank: {rank} , input shape: {output.shape}")
output.sum().backward()
optimizer.step()
序列并行
Colossal-AI 序列并行诞生的背景是 self-attention 的内存需求是输入长度(sequence length)的2次方,长序列数据将增加中间activation内存使用量,从而限制设备的训练能力。这是一种内存高效的并行方法,可以帮助我们打破输入序列长度限制,并在 GPU 上有效地训练更长的序列;同时,该方法与大多数现有的并行技术兼容(例如:数据并行、流水线并行和张量并行)。将输入序列分割成多个块,并将每个块输入到其相应的设备(即 GPU)中,并提出了环自注意力(RSA)《Sequence Parallelism: Long Sequence Training from System Perspective》。
Megatron-LM 的初衷是考虑通过其他方式分摊张量并行中无法分摊的显存,因此提出了序列并行的方法《Reducing Activation Recomputation in Large Transformer Models》。Megatron-LM 只是借用了 Colossal-AI 把 Sequence 这个维度进行平均划分的思想。在 张量的基础上,将 Transformer 层中的 LayerNorm 以及 Dropout 的输入按输入长度(Sequence Length)维度进行了切分,使得各个设备上面只需要做一部分的 Dropout 和 LayerNorm 即可。
这样做的好处有:
- LayerNorm 和 Dropout 的计算被平摊到了各个设备上,减少了计算资源的浪费;
- LayerNorm 和 Dropout 所产生的激活值也被平摊到了各个设备上,进一步降低了显存开销。
在 Megatron-LM 序列并行的这篇论文中,首先分析了 Transformer 模型运行时的显存占用情况。
Pytorch中的序列并行
# 通过设备网格根据给定的 world_size 创建分片计划
device_mesh = DeviceMesh("cuda", torch.arange(0, args.world_size))
# 创建模型并移动到GPU
model = ToyModel().cuda(rank)
# 为并行化模块创建优化器
LR = 0.25
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
# 根据给定的并行风格并行化模块,这里指定为序列并行
model = parallelize_module(model, device_mesh, SequenceParallel())
# 对分片模块执行多次前向/后向传播和优化器对参数进行更新。
for _ in range(args.iter_nums):
# 对于 SP,所有rank的输入可以不同。
inp = torch.rand(20, 10).cuda(rank)
output = model(inp)
output.sum().backward()
optimizer.step()MOE 并行
通常来讲,模型规模的扩展会导致训练成本显著增加,计算资源的限制成为了大规模密集模型训练的瓶颈。为了解决这个问题,一种基于稀疏 MoE 层的深度学习模型架构被提出,即将大模型拆分成多个小模型(专家,expert), 每轮迭代根据样本决定激活一部分专家用于计算,达到了节省计算资源的效果; 并引入可训练并确保稀疏性的门( gate )机制,以保证计算能力的优化。
与密集模型不同,MoE 将模型的某一层扩展为多个具有相同结构的专家网络( expert ),并由门( gate )网络决定激活哪些 expert 用于计算,从而实现超大规模稀疏模型的训练。
以下图为例,模型包含 3 个模型层,如(a)到(b)所示,将中间层扩展为具有 n 个 expert 的 MoE 结构,并引入 Gating network 和 Top_k 机制,MoE 细节如下图(c)所示。
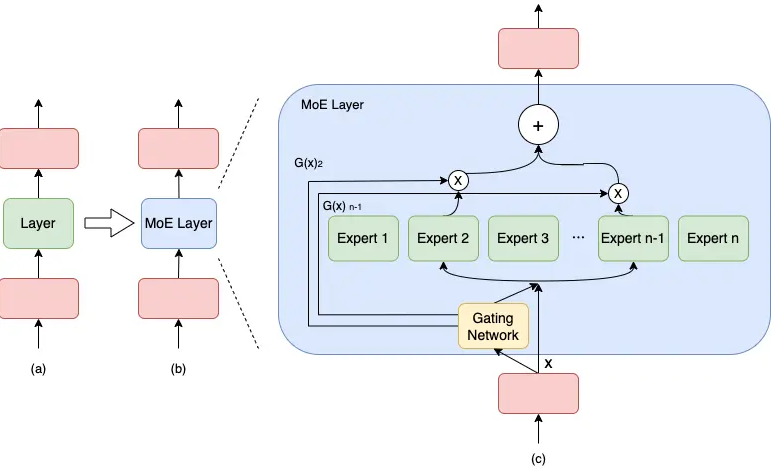
MOE分布式并行策略
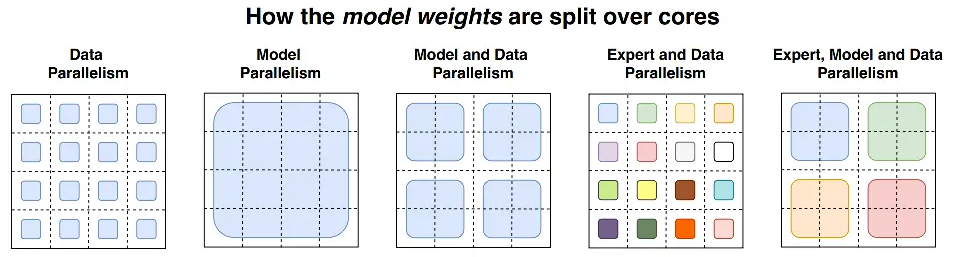
MOE + 数据并行:该策略是在数据并行模式下包含MOE架构,门网络(gate)和专家网络都被复制地放置在各个运算单元上。
MOE + 模型并行:该策略门网络依然是复制地被放置在每个计算单元上, 但是专家网络被独立地分别放置在各个计算单元上。因此,需引入额外的通信操作,该策略可以允许更多的专家网络们同时被训练,而其数量限制与计算单元的数量(如:GPU数量)是正相关的。
DeepSpeed 中的 MOE 并行
DeepSpeed中也提供了对 MOE 并行的支持。目前,DeepSpeed MoE 支持五种不同的并行形式,可以同时利用GPU和CPU内存,具体如下表所示。
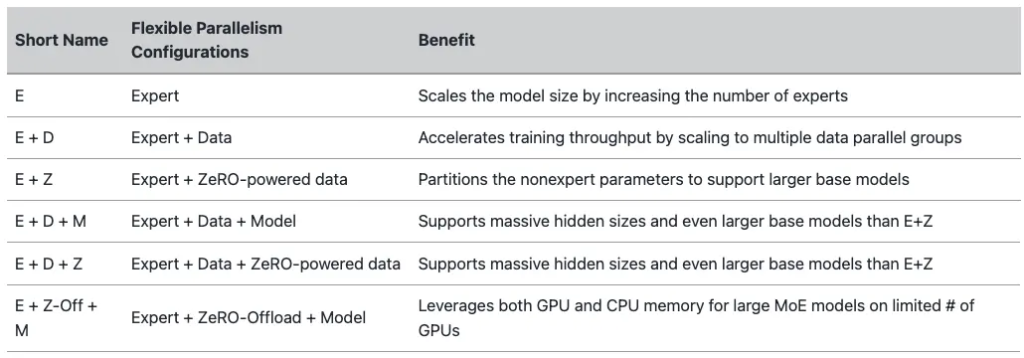
下面是使用 ZeRO-Offload (stage 2) 和 DeepSpeed MOE组合的样例:
# MOE 模型架构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
if args.moe:
# MoE 层
fc3 = nn.Linear(84, 84)
self.moe_layer_list = []
for n_e in args.num_experts:
# 基于专家数创建 MOE 层
self.moe_layer_list.append(
deepspeed.moe.layer.MoE(
hidden_size=84,
expert=fc3,
num_experts=n_e,
ep_size=args.ep_world_size,
use_residual=args.mlp_type == 'residual',
k=args.top_k,
min_capacity=args.min_capacity,
noisy_gate_policy=args.noisy_gate_policy))
self.moe_layer_list = nn.ModuleList(self.moe_layer_list)
self.fc4 = nn.Linear(84, 10)
else:
# 原始模型层
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
if args.moe:
# 将原始 FFN 层替换成 MoE 层
for layer in self.moe_layer_list:
x, _, _ = layer(x)
x = self.fc4(x)
else:
x = self.fc3(x)
return x
net = Net()
# 组合 ZeRO-Offload (stage 2) 和 DeepSpeed MOE
def create_moe_param_groups(model):
from deepspeed.moe.utils import split_params_into_different_moe_groups_for_optimizer
parameters = {
'params': [p for p in model.parameters()],
'name': 'parameters'
}
return split_params_into_different_moe_groups_for_optimizer(parameters)
parameters = filter(lambda p: p.requires_grad, net.parameters())
if args.moe_param_group:
parameters = create_moe_param_groups(net)
ds_config = {
"train_batch_size": 16,
"steps_per_print": 2000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [
0.8,
0.999
],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
},
"gradient_clipping": 1.0,
"prescale_gradients": False,
"bf16": {
"enabled": args.dtype == "bf16"
},
"fp16": {
"enabled": args.dtype == "fp16",
"fp16_master_weights_and_grads": False,
"loss_scale": 0,
"loss_scale_window": 500,
"hysteresis": 2,
"min_loss_scale": 1,
"initial_scale_power": 15
},
"wall_clock_breakdown": False,
"zero_optimization": {
"stage": args.stage,
"allgather_partitions": True,
"reduce_scatter": True,
"allgather_bucket_size": 50000000,
"reduce_bucket_size": 50000000,
"overlap_comm": True,
"contiguous_gradients": True,
"cpu_offload": True
}
}
# 初始化
model_engine, optimizer, trainloader, __ = deepspeed.initialize(
args=args, model=net, model_parameters=parameters, training_data=trainset, config=ds_config)
...多维度混合并行
DP + PP
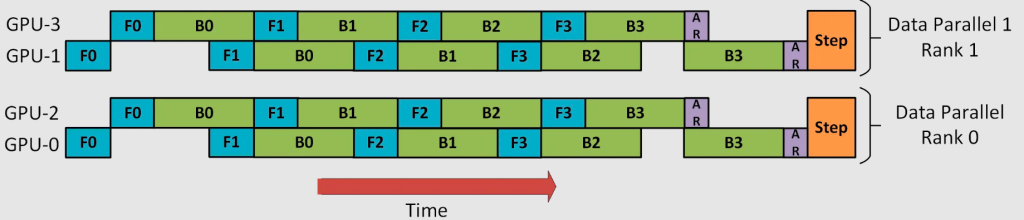
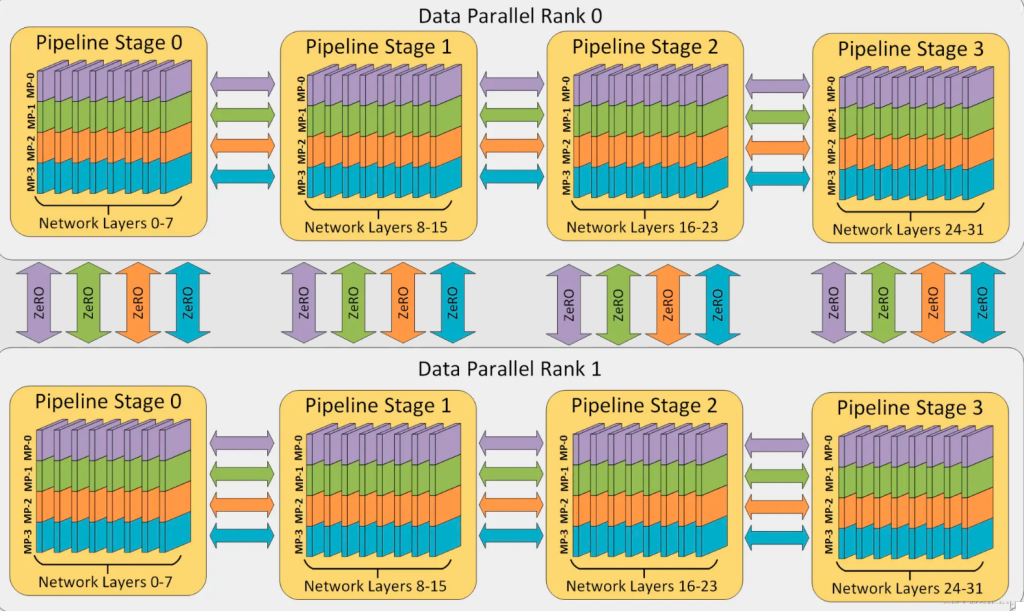
这里重要的是要了解 DP rank 0 是看不见 GPU2 的, 同理,DP rank 1 是看不到 GPU3 的。对于 DP 而言,只有 GPU 0 和 1,并向它们供给数据。GPU0 使用 PP 将它的一些负载转移到 GPU2。同样地, GPU1 也会将它的一些负载转移到 GPU3 。
3D并行(DP + PP + TP)
而为了更高效地训练,可以将 PP、TP 和 DP 相结合,被业界称为 3D 并行,如下图所示。
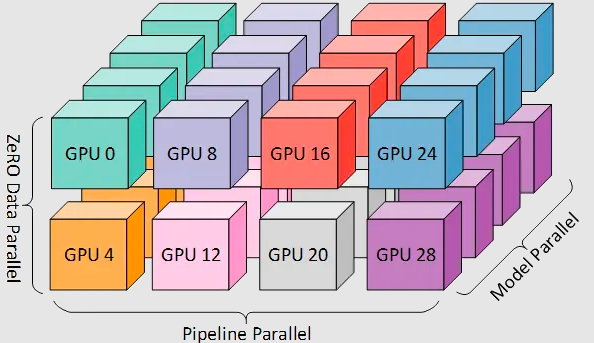
由于每个维度至少需要 2 个 GPU,因此在这里你至少需要 8 个 GPU 才能实现完整的 3D 并行。
ZeRO-DP + PP + TP
当 ZeRO-DP 与 PP 和 TP 结合使用时,通常只启用 ZeRO 阶段 1(只对优化器状态进行分片)。